High-Performance OPA
Transpiling Rego policies into C++.


Intro
The Open Policy Agent (OPA) is broadly used to evaluate and enforce application security policies. The OPA engine is open source. Its primary implementation is in Golang, and there also exists a Wasm solution.
When Dima started looking into OPA late last year, the major challenge was how to evaluate policies that require local access to tens of gigabytes of dynamically changing data. Golang is not known for its low memory footprint, and research started. Among other possible solutions, the authors of OPA pointed to the Intermediate Representation (IR) of policies as a possible path. The IR is what the OPA engine can output as an intermediate step, after the source code of the policy is parsed, but before this policy is applied to the input data to evaluate the result. It soon became clear that using the IR can be used to solve the RAM footprint problem — and a few others too.
There are two generic ways to evaluate a policy having its IR: interpretation and transpilation. To interpret an IR of a policy is to build a parallel OPA engine. To transpile the IR is to auto-generate a piece of self-contained, optimized, and, in our case, strongly typed code that implements a function to natively evaluate this particular policy, while remaining within the realm of the target programming language.
Transpilation
Compared to interpretation, policy transpilation is the road less traveled. We decided to explore it. The first experiments were with JavaScript. Later on, for performance reasons, as well as because we speak it best, the target transpilation language became C++.
Generating code automatically from an original higher-level source is a common build step these days. For example, using gRPC and protocol buffers involves a build step of generating source code from protocol definition files.
Two major low-hanging fruits to pick with transpilation are:
Performance and RAM usage. Transpiling OPA policies into a low-overhead programming language, such as C/C++, enables OPA policies to be evaluated on platforms with tight CPU and RAM constraints.
Static checking and type safety. OPA Rego is not a strongly typed language. Transpiling Rego into a strongly typed language, and specifying schema for the input, organically infers typing internally, which both boosts performance, and helps catch errors early on.
On the performance front, there are plenty of use cases for OPA where it is not feasible to bring in the Golang runtime engine. These are the cases where HTTP, and even JSON, are quite a bummer in and of themselves. For such applications, a JSON-first API is a non-starter, while a native function to evaluate the policy is an ideal way to go. This makes transpiling OPA policies immensely valuable in the embedded / IoT world. Low-overhead high-performance policy evaluation also makes it possible to use OPA closer to hardware, such as at edge computing, CDN nodes, or network-level load balancers.
Benchmarking
The performance tests, run against the policy from this OPA blog post, result in:
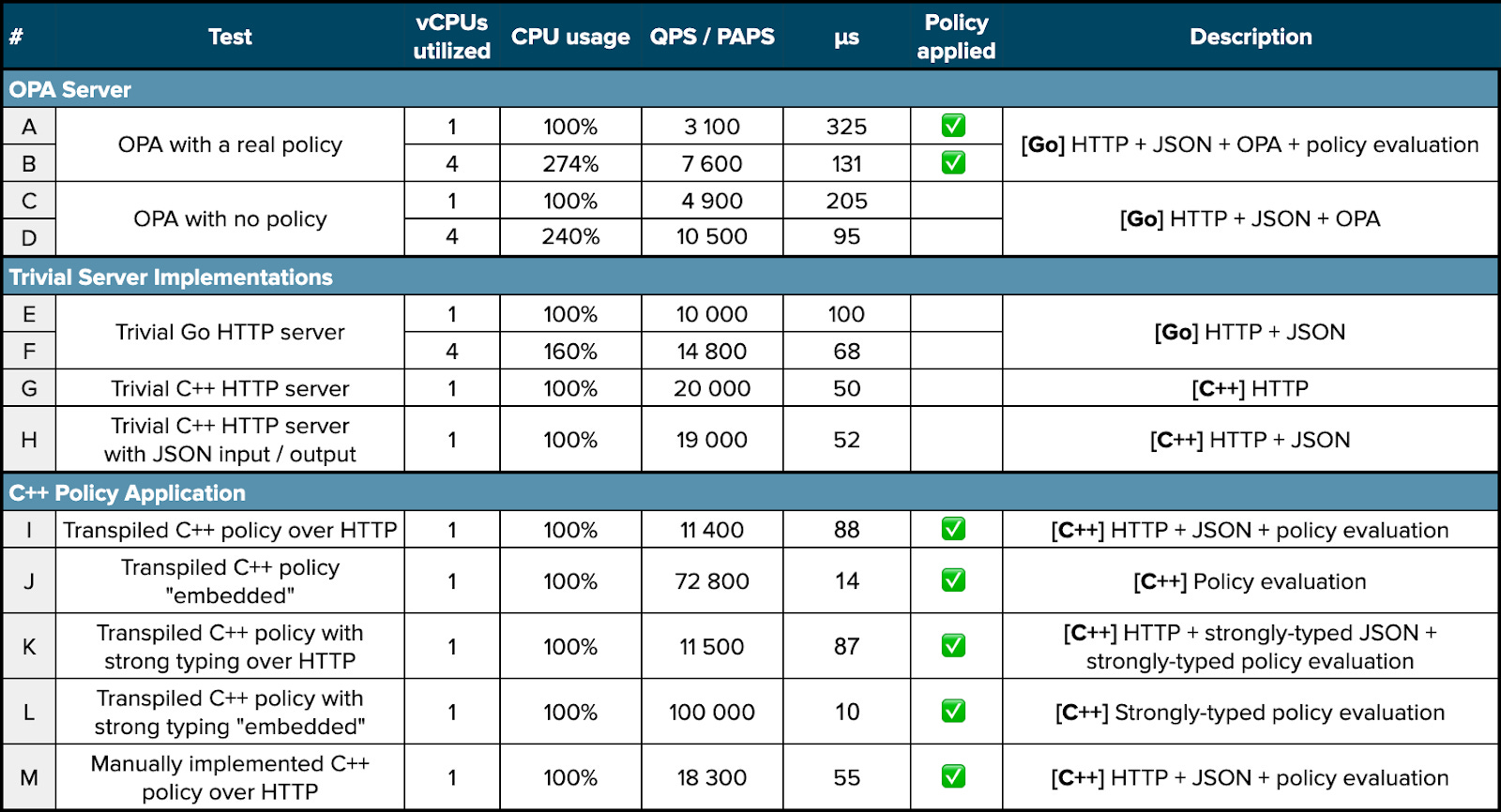
Here are the instructions on how to reproduce each of the steps. The tests are run on a t2.xlarge AWS EC2 instance. The relative numbers should be the same on any machine.
vCPUs
A few notes on performance before diving into the numbers:
The tests are run locally, and the HTTP requests go to localhost. All the server-side code and the test runner can work across machine boundaries. Setting up a reproducible multi-machine test requires more time than there is weekend though.
The t2.xlarge box has 4 vCPUs, but some of them, about 150% of 400%, are used up by the test runner. Hence the CPU usage column in the table, which is the output of the top command while running the respective test.
OPA is implemented in Golang, which natively uses more than one CPU core. To make it easier to interpret the results, for each Golang run there is an extra row: the same case executed with GOMAXPROCS=1, which limits the Golang runtime to one CPU core.
Experiments
All experiments are based on running the same 100K random queries against the test policy. The queries are generated such that for slightly over 5% of them the outcome is {"result":true}, and for the rest it is {"result":false}.
Baseline
The baseline case is to run the OPA server, import the policy, and run all the queries against it. For this, an official v0.42.2 OPA binary is used. Using OPA from a container yields same results..
These baseline runs are rows (A) and (B) of the table. Row (B) is the most generic case, and row (A) is limiting Golang to one CPU when running OPA. Thinking of embedded first, performance per CPU is what interests us most. As per-CPU performance is a bit higher in the single-CPU run, let’s establish the baseline of OPA-run policy at 3’100 QPS per CPU core, or about 325us per query. That’s row (A).
Treating OPA as a black box, it is tempting to get a bit more insight into what is happening during these 325us. One way to do it is to run the same queries against a freshly started OPA, with no policy loaded into it. Certainly, the responses would not match the expected ones, and, about as certainly, the QPS would go up. Rows (C) and (D) contain the result of this run, and the higher per-CPU number is in row (C), at 4’900 QPS, or 205us per query per CPU core.
To get a pure Golang baseline number, here’s a dummy 20 LOC Golang HTTP server. Benchmarking it results in rows (E) and (F), which show that a boilerplate Golang server, that does nothing but respond to HTTP requests, can handle 10’000 QPS, for 100us per query per CPU.
Before comparing OPA to transpiled C++, we also wanted to get the baseline number for an HTTP server in C++. With Current’s native implementation, rows (G) and (H) are the numbers for a single-threaded C++ HTTP handler. Without and with JSON body parsing respectively, the numbers are 20’000 QPS and 19’000 QPS, or 50us and 52us per request per CPU core.
Nice round figures are easy to work with. Keep in mind these dummy runs are just reference benchmarks, they do not evaluate the OPA policy.
Transpilation
Back to the transpilation territory, where the tests are real, the policies are evaluated, and the results match the OPA-generated goldens.
The most straightforward benchmark of a transpiled OPA policy is to spawn it as an HTTP server. The resulting transpiled code allows doing exactly that, with ./transpiled -p 8181 -d, as per this README file.
This run can be directly compared to OPA, and its result are in row (I) of the table. The number is 11’400 QPS (88us) per query, to be compared to rows (A) and (B).
Since the transpiled C++ code is what we have full control of, it’s tempting to benchmark it evaluating the transpiled policy in an “embedded” setup. The “embedded” setup is to evaluate the policy by calling a native, auto-generated, C++ function, without the HTTP and the JSON parts. The very test still accepts — and writes! — JSONs, but input reading and parsing, as well as output generation and writing, is done outside the metered section .
In such a setup there are no independent queries, and the term QPS would be a bit of a stretch. Let’s refer to this number as Policy Applications per Second (PAPS) instead. The measurement comes back at 72’800 PAPS (14us), and this is row (J) of the table.
Strong Typing
For the rocket science part, behold strong typing enter the game.
For rows (I) and (J), the input to the policy evaluation function is merely an “object”, or, if you wish, a dictionary. We, the humans, know it consists of a single-key object within an object (the `.input` part), and that this `.input`, in its turn, contains three strings, under the keys `.input.user`, `.input.action`, and `.input.object` respectively. But, without typing, the CPU does not have this assumption.
While this input JSON is “JSON-parsed” prior to evaluating the OPA policy, the very act of accessing each of these fields requires looking it up — by name, in a dictionary. This is not to mention that the field might be missing, or that it may be of the wrong type. All these checks result in extra CPU cycles, that are applies on multiple steps during policy evaluation. In reality, these checks can happen only once, during the input validation. Or, ideally, these checks can happen zero times, assuming the caller of the function can not possibly forget to pass certain fields, as doing so would result in a static type error, far earlier in the build process.
With the power of C++ templates, most of this strong typing work is taken care of organically. The transpiled policy code is implemented in a generic fashion, and it naturally makes use of being able to directly access fields such as `.input.user`, as long as this field is present in the input type. Effectively, it’s a two-in-one function:
When invoked for a generic object, field lookup works on a “dictionary”, and
When invoked for a typed structure, the respective fields are accessed directly.
And if invoked on a type with the wrong field(s), it’s a compilation error.
Here is a commit with a minimalistic diff, in which the two types — one for the top-level `.input` and one for the inner `.{user,action,object}` fields are introduced, and in which the generic `JSONValue` expected input type is replaced by the fully-specified one. The rest magically happens behind the scenes thanks to C++ templates.
Benchmarking with the above diff applied, when running queries over HTTP, row (K), to be compared to row (I), shows a modest improvement: from 11’400 QPS to 11’500 QPS.
This still is the use case in which the transpiled code exposes the very same HTTP + JSON interface that the OPA server does. As expected, even when using C++, the HTTP + JSON parts are too heavy compared to the very logic of evaluating the policy, so the improvement is relatively modest.
In the “embedded” use case, where the HTTP + JSON part is taken out of the equation, row (L), compared to row (J), improves the number from 72’800 PAPS to a nice round 100’000 PAPS. In other words, introducing strong typing reduces the time it takes to evaluate the policy from 14us to 10us respectively.
Before wrapping up, let’s do a quick headroom estimate. This short snippet is a straightforward rewrite of the same OPA policy into C++, and, in row (M), it performs at 18’300 QPS (55us) via HTTP. Row (M) is to be compared to row (H), 19’000 QPS (52us), where the (identical) HTTP + JSON part is present, but the policy is not evaluated.
That these numbers are so close to one another — 50us HTTP vs. 52us HTTP + JSON vs. 55us HTTP + JSON + policy — suggests once again that, at microseconds scale, HTTP and JSON are what’s taking up most of the time. In the embedded use case they are too wasteful, and best to be avoided. Transpiling Rego into C++ is the way to go there.
Under the Hood
As the implementation stands now, the IR is first converted into a DSL, friendly to be treated by a good old C preprocessor. (In fact, to see ths DSL, replace `rego2cc` by `rego2dsl` in the example command in the README above.)
Converting this DSL into a functional JavaScript code takes one pass. Converting it into C++ code is a two-pass process:
A piece of C++ code is generated on the first pass.
It then is built and run, diligently analyzing the internals of this IR.
And the result of this run produces the final C++ code that evaluates the policy.
This seemingly redundant step (2) is to simplify the difficult task of inferring intermediate types. The IR of an OPA policy uses a lot of intermediate “locals”. In an untyped world — such as with JavaScript — all those local variables are just `var`-s; in fact, they can fit one `Array`. In the strongly typed world:
Field accessors are not dictionary-based, but type-based,
Numbers, such as indexes or counters, can be represented as, well, numbers,
Redundant checks, such as type checks that are now static, can be omitted, and
Unused inputs can be omitted, so that output-only functions become singletons.
With a bit of work, transpiling into plain C should also be doable. It might require three passes though, as `decltype` and `auto` are present in C++, but not in C. It would be an exciting exercise if the stars align. Besides, squeezing more out of the C++ implementation may also benefit from extra steps, as the transpiled code, compared to how it looks now, can clearly be more readable, more concise, and more performant.
HTTP and JSON
Here is a good place to pay a tribute to Current and to RapidJSON.
Current, our header-only C++ framework, originally designed to help with realtime ML tasks, contains a lightweight HTTP server. It continues to show great performance, even when compared to a bare modern-day Golang implementation.
Current uses RapidJSON, the C++ JSON library, for serialization. Its performance numbers also continue to be impressive, and RapidJSON is solidly in the tops in its category according to various benchmarks.
Conclusions
Kudos to the OPA team for exposing the IR and for sharing its documentation. Dealing with the IR is not a trivial task, but, admittedly, it took less time than anticipated, and it was a pleasure to work with.
The current OPA to C++ transpiled code is far from optimal. Its performance can be improved further. 10 microseconds per policy application is fast enough for all intents and purposes though. Most doors that could be open by a 3-micros or by a 300-nanos implementation are likely wide open by the 10-microseconds solution above.
The 100’000 policy evaluations per second figure, incredible as it looked when this experiment started, looks mundane now. It was an exciting exercise, and this approach can help OPA run far more use cases on far more devices and platforms.
 | A guest post by
|